It’s an odd time culturally in UX research, I’m not sure any previous tech has sparked a debate in UX research quite like AI. For that reason, I need to state my position up front. I’m not an AI hater. I use it all the time. While AI did not write any of this article, multiple providers and models acted with me as searchers, sparring partners, and editors. That said, I have deep doubts about AI. Sometimes I see the excitement lead people to forget our fundamentals due to the shininess of a new process. AI moderated interviews fit here.

I’m also not a staunch interpretivist like the 419 researchers that signed a letter asserting the necessity of human connection to qualitative work. In certain contexts, the moderation of a session with AI can be the right choice for the UX research domain. But in most cases right now, it falls short of rigor or a researcher’s project goals. Anthropic’s 80,000 user interview project is in the limelight or in the hot seat depending on what your relationship is to research as a discipline. It provides a nice case study for my perspective on AI moderated interviews. I reference this as a case study, but my thoughts here apply to the method more broadly.
Some things seen in the study are clearly problems of quality. The “interviewers” ask narrow questions, they can’t read well into non-verbal cues, they don’t build much rapport, and they have a hard time keeping up with nuance in follow up probes. The technologist in me sees that these things are valid but temporary arguments against the method. LLMs may get better or a brand new type of machine learning model may crack these issues. However, those problems are execution, not the fundamental approach.
The more interesting area for me to discuss is what is fundamental to the current use of AI moderated interviews that reduces rigor and value of the method.
The “new” method
Papas said that both qualitative researchers reject it as interviews and quant researchers reject it as a survey. His article does a great job exploring what the trade offs are from interviews and surveys when using this new mixed-method approach from a theoretical perspective.
This isn’t to say everything is the same as before with the method. Of course, one major challenge of qualitative research was scale. It’s expensive and time-consuming to do interviews with many sub groups . AI moderated interviews allow for a scale that is 10x-1000x previous human-led paradigms.
Surveys used to be the main method to reduce bias that comes from face-to-face interactions. Now, a distinctly qualitative method also allows for this. Whether or not this is truly effective remains to be tested empirically (especially considering humans tend to treat computers as social actors anyway).
While Papas accurately pegged the discourse and concern from researchers of all traditions, I’m not sure I agree with it. This methodology shows something I see novice UX researchers do all the time: a qualitative input with primarily quantitative output. AI moderated interviews as they have been run are just a qualitative project at massive scale, making the mistakes of a lost positivist.
The fundamental issue
The reason I see this method as a failure hinges upon the nature of qualitative vs. quantitative research. I normally like to define my terms in detail up front, but that post isn’t done yet, so you’ll need to take me at my word until I update with a link to a much more thorough unpacking. Here’s how I define the two strands of research:
Qualitative research: identifying the elements of interest.
Quantitative research: establishing magnitude or prevalence of those elements of interest.
I use the term strand as it is common in mixed-methods academic work to talk about how a researcher moves between and through various paradigms in a mixed-method project1.
Point of interface: the irreconcilable mixed-methodology problem
AI moderated interviews, in their current use, run into systemic problems of rigorous execution. Perhaps the most common mixed-method design in UX research is exploratory sequential design: start with qualitative research to define what you care about by generating or uncovering the things you want to count, then use quantitative work to count those things you care about differentiating.
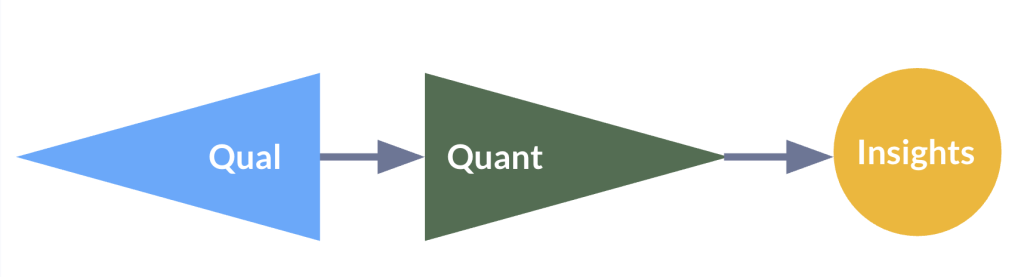
The “point of interface” is the moment where a strand of qualitative work intersects with a strand of quantitative work. It’s useful because it’s a traceable moment where the goals and bounds of one research tradition give ownership over to another. Qualitative research is excellent at uncovering new things to count in human experiences, but poor at assessing scale to positivist standards. Quantitative research is excellent at assessing scale but lacks the nuance and fuzzy scope to uncover brand new things to count.
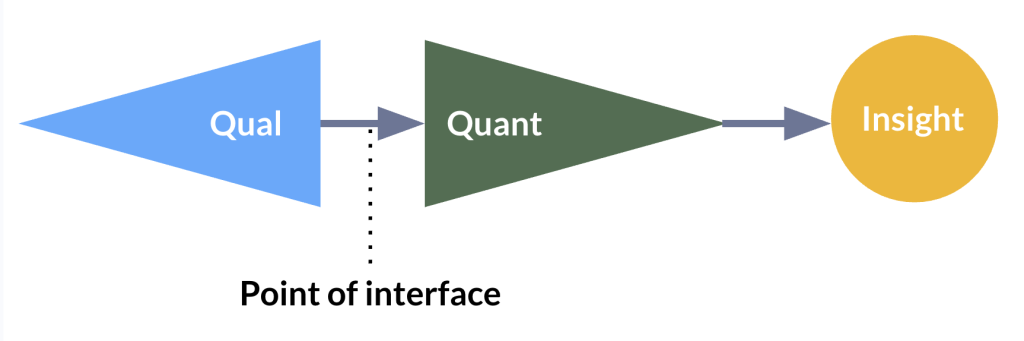
AI moderated interviews collapse the exploratory sequential design into a single moment, identifying elements of interest while they establish prevalence. The classifier prompts simultaneously define what counts as a category (generative, qualitative discovery) and count how many people fall into it (evaluative, quantitative justification). Why is this a problem for our method? It’s a problem for research in general, whether human or AI, because you can’t effectively count “it” before you know what “it” is.

Let’s say that a researcher produces a finding from AI-moderated interviews like “18% of people hope for professional excellence from AI”. The finding here is produced from a conjunction of methodological choices that are unexamined and unexpressed. For the sake of argument, let’s be extremely detailed. Here is are just a few key assumptions that underlie that insight about hope for AI:
- The AI probe reliably elicited AI usage-relevant responses rather than satisficing answers.
- The coding scheme correctly identified expressions of uncertainty as a distinct category.
- Different probe paths across respondents activated the same underlying construct.
- The categories are sufficiently exhaustive that this percentage is not an artifact of what was left out of the coding frame.
- The sampling frame and response group effectively represent the population.
The important split happens between 3 and 4. Assumptions 1–3 fall within the qualitative strand: did we generate the right categories from what people actually said? Assumptions 4–5 fall within the quantitative strand: are we counting those categories in a way that holds up?
The problem here is that an AI moderated interview technique applies competing research paradigms at once. It’s measuring something it constructed before the data had a chance to say what it actually contained. In plain terms, we don’t know if the categories were sufficiently exhaustive before stacking them up against each other. When we look at the analysis, it becomes a problem when researchers present findings with an expectation of positivism by providing percentages assumed to be representative of a broader population.
Acontextual counting: don’t quant the qual
I will acknowledge that failing to uncover exhaustive categories is less likely when sampling from 80,000 people. However, even if we uncover all the possible categories, these are not necessarily examined across all users equally. The method relies only on participants recalling their experience from broad prompts, introducing its own bias. Each response category is not necessarily equally weighted in a person’s recall. This is where a deeper analytical problem emerges: even with exhaustive categories, counting them naively breaks the research.
One of my professors in graduate school warned, “don’t quant the qual”2. It’s an easy trap to fall into when most of us live in a world that is decidedly positivist and holds counting as the most valuable action in science.
When each participant’s utterance is coded and weighted equally (whether by human or AI), this mistake is called acontextual counting. The problem is that all utterances and patterns are not equal to the categories that define a phenomenon.
A pattern mentioned by 200 people can plausibly unlock a mechanism behind a behavior or attitude that is much more important than a surface level pattern noted by 5,000 of the 80,000 people. In the current process that squashes generation and evaluation together, the “researcher” has no chance to realign to what is truly important to the construct of interest. The AI moderated interview approach naively and crudely quants the qual, counting each set of tokens with the same weight as any other. This is the shallow meaning-making that leads many current AI-led research approaches to produce “true” but banal insights.
AI-moderated interviews skip the point of interface. They compress what should be an exploratory sequential design into a single pass, privileging the common over the explanatory and the surface over the generative mechanism. This is what I mean by a lost positivist: the current method shows what an overly dedicated quantitative researcher would attempt to do with an infinite qualitative toolkit, missing the point of the interview method entirely.
Qual and quant strands can exist well in studies together, like using open text information with surveys to provide context and color to primarily quantitative analyses. I do this often, but there is a “strand priority”, the qual is supporting the quant. If there is a really interesting nugget that comes only from qual, it’s marked as such and not said to provide the same type of information as the main quantitative strand of work. The Anthropic study, and AI-moderated/analyzed interviews in general, lack a strand priority.
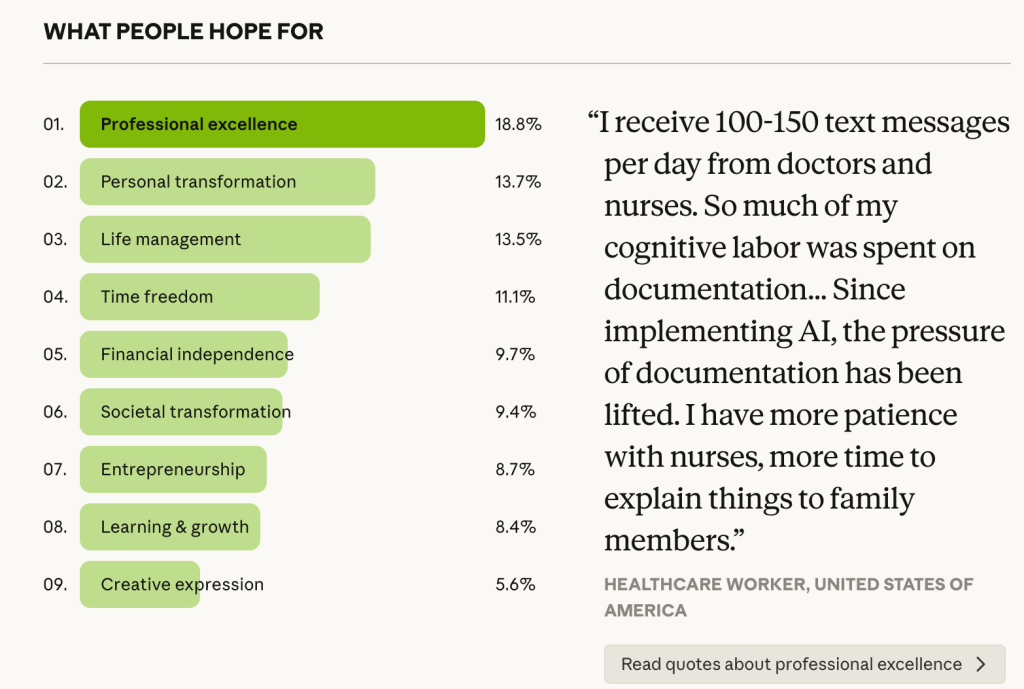
You can see in the findings that the quantitative strand is given a lot of dominance. The information in this image is much more dense quantitatively, with 9 categories and percents in a chart, as opposed to one qualitative quotation. The issue is that these data were generated through a qualitative process and these distinctly positivist percentages suffer from acontextual counting.
Lack of a strand prioritization is not just a problem in theory. It means the work is not rigorous, resulting in a warped lens promising to be sharply focused. This makes teams follow bad paths and rest on false insights, leading to bad organizational outcomes.
Where we go from here
Like I said at the top, I’m not an AI hater. We can use AI to massively scale research in a world with the right models and thoroughly tested processes. I completely agree with Papas in this case (and what I think is also the case for most AI research tools right now): we need frameworks for what works well with a given method and we need to do the work to test that empirically.
The approach from Anthropic feels like someone building a house who has a vested interest in hammers. They want to make houses better and faster by making the hammer as best as it can be. We could probably do better by making hammers better, but also making drills and wrenches better too, and then having each tool do their job. The project from Anthropic is impressive in many ways, but is really a demo for the AI interviewer tool. I am a big fan of Anthropic’s products, and with some other tools from them (like their agentic offerings) we could do even better than interviewing 80,000 people.

I mentioned some positives of this method throughout my discussion so far. AI moderated interviews can reach a massive scale of people quickly in a generative research context. This makes things like failing to find exhaustive categories unlikely and increases the ability to get a positivist “representative sample” from an interpretivist qualitative method. Despite these strengths, the current approach from Anthropic is just quanting the qual, applying positivist analytical methods to a qualitative, interpretative data generation process. Mixed-methods designs exist for a reason, 1000x-ing the scale doesn’t change the fundamentals. Even if AI models get better, humans will still be humans, and they’re going to be at least half of the equation in a research project.
The 80,000 interview number is truly a paradigm shift for qualitative work, but what does it solve? Saturation is critical in qualitative research, ensuring a researcher uncovers the necessary amount of data when we can’t apply a statistical power analysis method to estimate our ideal sample size. Even across hundreds of countries, saturation is likely to be reached well before 80,000 interviews.
How can we use AI to make all of our tools better rather than applying one tool to problems it wasn’t designed for?
A classic mixed-methods approach
We could feasibly make a classic mixed-methods, AI-led study design that uses qual and transitions to quant in a traceable point of interface that maximizes the strengths of each. Instead of fielding 80,000 AI-led interviews for a week, that time could be split across iterative qualitative AI analysis, and a more classic survey. Here’s how it could look as an AI-led explanatory sequential design:
- Qualitative strand
- Develop a focused research question and target population, design a discussion guide.
- Wave 1 with AI interviewer (50 interviews per country): Sample for variation across user types; after collection, run multiple AI-prompted classifiers to extract themes, stop data collection for stable themes.
- Wave 2+ with AI interviewer (50 interviews per country): Sample and analyze data again, look for more stable themes across a multi-classifier analysis. Note negative case analysis theses (counter evidence).
- Enforce a saturation gate to decide when to stop iterative waves: do not proceed until no substantive categories, no revised definitions, and no new negative case patterns appeared in the most recent wave.
- Taxonomy finalization: Run the finalization prompt to audit for exhaustiveness, mutual exclusivity, abstraction consistency, and behavioral vs. attitudinal items before drafting final constructs.
- Quantitative strand
- Draft the survey instrument with a drafting agent. Use multi-select or single-select battery questions for prevalence, Likert items for magnitude of constructs, or MaxDiff for prioritization. Review the draft with a prompt to assess basic survey design quality.
- Cognitively test a pilot with 20 users per country using the AI interviewer. Revise based on these results.
- Sample for representativeness at the minimum N for each desired sub-group analysis.
- Run an automated analysis to understand prevalence of key attitudes/reported behaviors across groups, and assess relationships across variables.
With AI leading the execution across all phases, I doubt it would take much more time than brute-forcing 80,000 interviews, once prompts and agents are properly designed/built. For participant incentives, it could cost quite a bit less as well considering that surveys are a fraction of the cost of an interview (even with AI, a survey should take less time than an interview).
Most importantly, this would create traceable points of interface and overcome acontextual counting through distinct iteration. These problems cannot be resolved by doing 80,000 AI interviews — it’s in the nature of the process. We have to account for strand dominance and make points of interface explicit. This is nothing new, it’s just a more varied application of AI across a classic research process.
Wrapping up
I don’t think the current models are effective enough that the quality would be as good as a human owning more of the process, let alone better than humans. I do think this hypothetical would work better than 80,000 interviews when we interrogate the way we arrive at our findings. There is a reason we have interviews and surveys. It’s because they’re each the best way we’ve found to research their respective slices the human experience, not because it was hard to interview 80,000 people.

We’re having this conversation now because previous resource constraints no longer exist. However, humans still come with similar capabilities and biases. Whether a blessing or a curse, we need to start asking not just if we can interview 80,000 people, but if we should.
Appendix
- Teddlie, Johnson and Tashakkori defined a strand as a component of a study that encompasses the basic process of conducting quantitative or qualitative research like posing a question, collecting data, analyzing data, and interpreting results. This is the canonical definition, used throughout the Creswell and Plano Clark framework as well ↩︎
- Dr. Elon Hope said this in my qualitative methods class at NCSU. I highly recommend a core qualitative methods class to all aspiring UX researchers in graduate school – I learned so much. It turns out most (if not all) qualitative methods we use in UX research have roots in academia. ↩︎