
tl;dr
Strategy/tactics definitions conflate generative/evaluative research with large/small scope research. Evaluative work can be impactful at a strategic level when it appropriately covers the scope of a system. Generative work can be tactical when it’s constrained to be too focused within existing product offerings.
Background
It’s a common conversation lately in UX that teams need to focus on strategic research rather than tactical research. Strategic research finds ways to differentiate, “a plan to win”, while tactical research is how the plan gets implemented (Friedland).
Articles call out that teams are too focused on tactical work, leaving UX teams with little influence, dealing only in quick wins (Spool, Piqueras, Renwick). The strategic research is explained to be loose-structure discovery user interviews and tactical research portrayed as small scale usability testing. There is the sense that strategic work is valuable, but tactical work is done to the detriment of UX teams’ broader goals.
An article by Raz Schwartz starts to break this down to show how “tactical” research is extremely useful to UX teams. One key point is that tactical research can be rigorous and influence strategy: results can be triangulated from multiple methods and counter fundamental assumptions a product team has. If tactical research can influence strategy, do these definitions really make sense? Where does the confusion come from?
Towards new definitions
The value and impact of tactical research is hidden away because the tactical/strategic model collapses two more descriptive dimensions: generative/evaluative and large scope/small scope. Generative research uncovers new user needs/problems, while evaluative research assesses quality in an existing product. Another common explanation is building the right thing vs. building the thing right. These definitions are focused on the theoretical research goal of the methods used.
I propose the definition of large scope/small scope as the coverage of what a research method is able to get insights about.
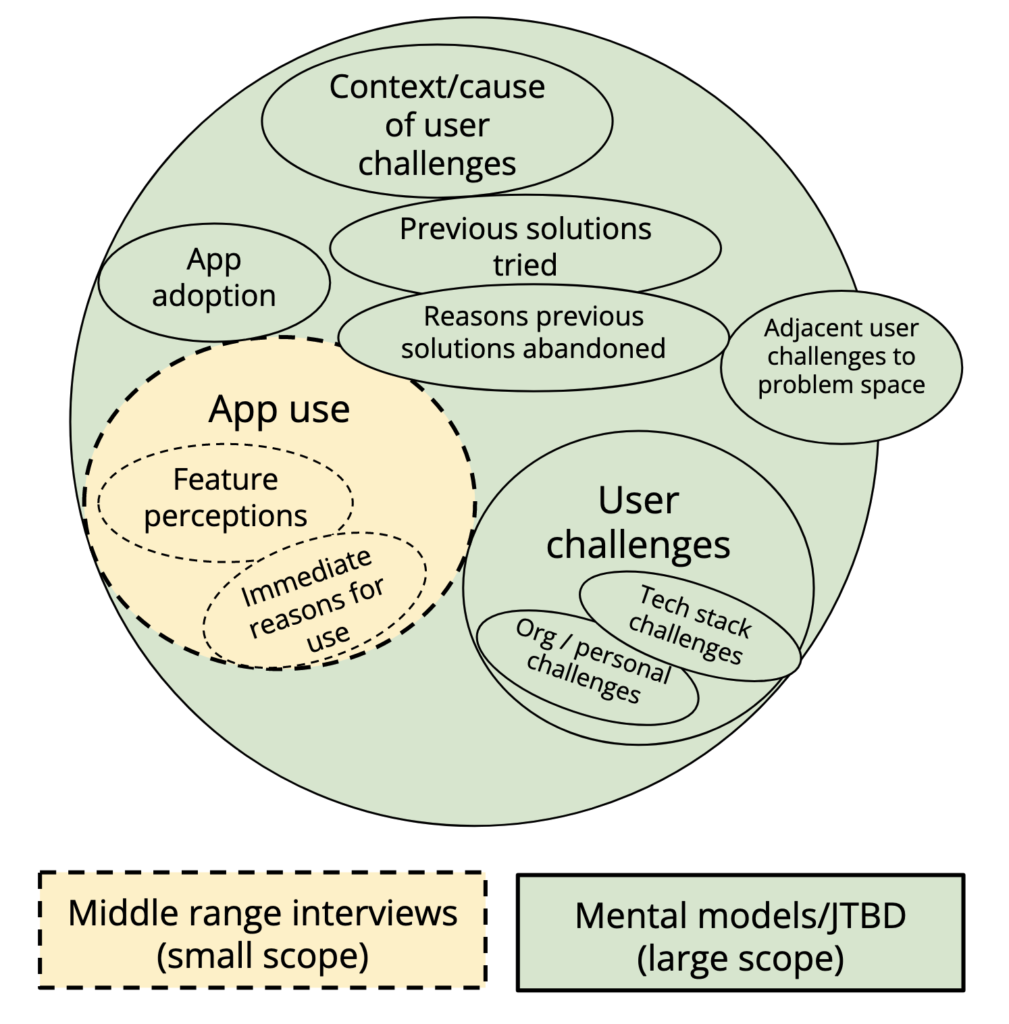
In generative work, this is going to be the domain coverage of user needs and problems – how many areas of a user’s context could the method uncover new insights about?
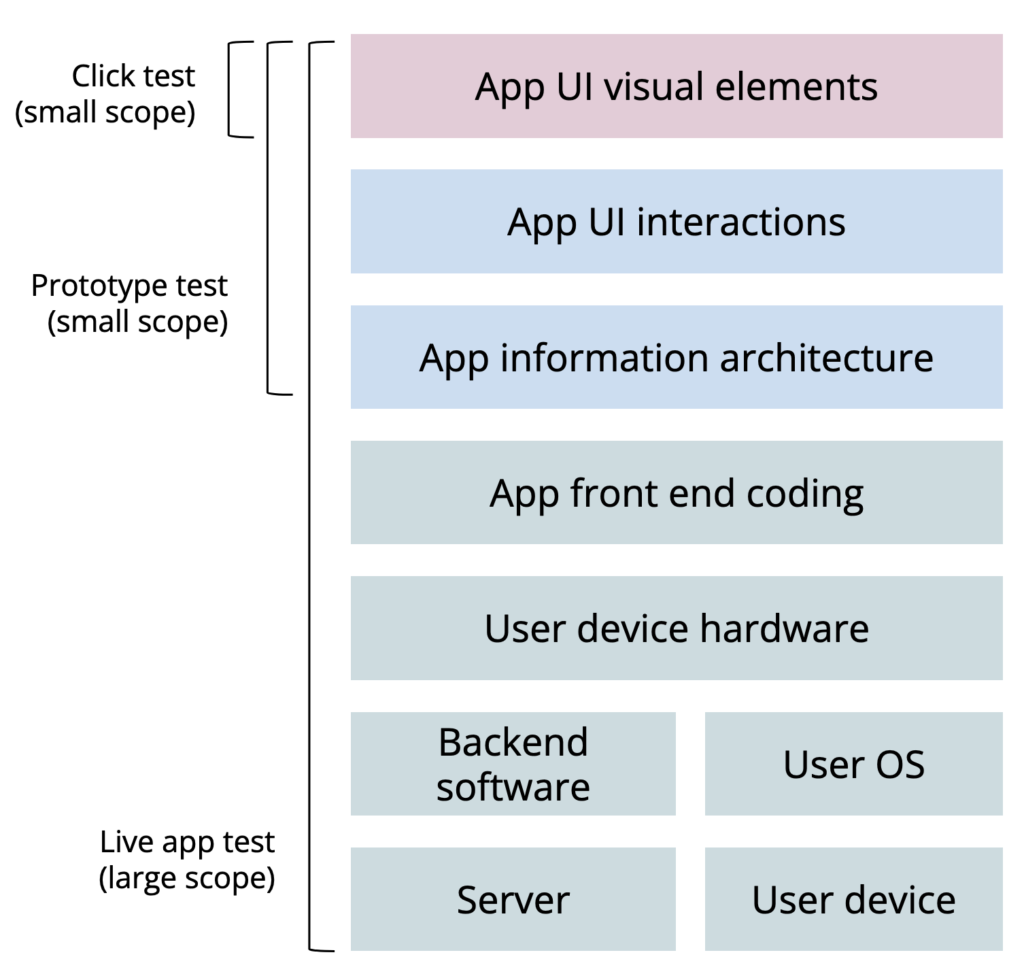
In evaluative work, this is the domain of what is being tested – how many systems or how much of a system is being tested with the method?
Large scope/strategy and small scope/tactics have a lot of overlap in what methods are used with each type.
Common methods across dimensions
| Generative | Evaluative | |
| Large scope method (strategic impact) | Mental model interviews Jobs-to-be-done | Live app usability testing Usability benchmarking |
| Small scope method (tactical impact) | Middle range user interviews (“Why don’t you like this feature?”) | Prototype testing Interaction testing First click testing |
So what is the difference between the concepts of strategy/tactics and scope? Scope focuses on what researchers can control in the project planning phase: the potential areas the method will uncover insights. Strategy/tactics focuses on impact of the research on the organization, something a researcher can hope for but not plan on. In fact, much of a study’s impact goes beyond the method itself and into things like readout plans, connections with product management/leadership, etc. A researcher can’t know if the impact will be strategic, as it’s unknown what the insights of a research project will be beforehand. Think of it this way: an Olympic diver doesn’t plan a 10/10 dive. They plan a dive that is sufficiently complex and technical it might get a 10/10 score. Strategic research is the outcome (10/10 score), but you have to plan sufficiently large scope research it will reach strategic impact (complicated dive).
The difference between scope and strategy/tactics is nuanced, but using this two-dimension framework better serves researchers because it shows how robust evaluative research can influence strategy and should be part of any long term research roadmap. It also shows how generative work can be less useful than it’s expected to be. If we keep using our old framework strategy/tactics, we miss out on lots of valuable, essential research to plan.
The broader UX discussion still assumes that generative work is large scope and evaluative work is small scope. Let’s investigate why this isn’t necessarily the case.
Evaluative research across large and small scopes
Warily veering into anecdata, every company I’ve worked at has known about major problems in their product’s usability, whether B2B or B2C, whether 50,000 users or 1,000,000,000 users. Usability, in my experience, is a hard problem for every product and product team. UX teams try to address this with evaluative research, but it’s frequently planned to have a smaller impact than it could.
Evaluative research is often relegated to the small scope. Say a team wants to improve their product’s usability, they work harder in the design phase to test prototypes with users and ‘get ahead’ of the usability problems. This is well-intentioned and not necessarily a bad thing. When prototype testing is the only evaluative research done, then product teams get in trouble. Ultimately, when testing the prototype, you get results about the prototype, not the full product. The prototype testing is small scope: the content is cherry-picked, the interactions are limited, the responsiveness is that of Figma or Adobe XD, not the real product tech stack. Only the design team/UX team sees much impact with small scope evaluative research, because results only pertain to prototypes that design/UX owns.
Large scope evaluative research
Testing a full product with a live app (or system) is large scope. The content is naturally populated and not picked to neatly fit the design constraints. The interactions reveal intuitiveness to users based not just on the design, but how a front-end developer implemented each element. The responsiveness is based on how clean the front-end code is and how effectively the core engineering team structured the back-end databases.
When a team does evaluative testing with a larger scope (even with a small N), the impact can be huge to the point of influencing the organization across teams. If the app is too slow for users, now the back-end engineering team is involved to overhaul the main code base or the executives consider if platform speed is something the product can compete on. If users are confused by the content, now the machine-learning team may need to re-think its model for how content is fundamentally categorized.
In addition to working with prototypes, usability work is typically set in an iterative, small N context. This can be extremely useful to improve designs early on. With mature products, usability can and should be researched in a large N benchmarking context. Usability benchmarking can measure the impact of the UX team on the product, compare to competitors’ UX, and continue to provide the same qualitative insights as small N usability testing. By scaling up usability testing and expanding the scope, UXR teams begin to get numbers that executives pay attention to. It helps researchers get a seat at the strategy table (even through evaluative work).
Researchers need to unbuckle evaluative work from the small scope to make high quality products. Evaluative work can become “strategic”. Going back to our original definition of large scope/strategic, we may come up with a new plan to win based on how our product usability compares to key competitors in benchmarking or how users perceive the content taxonomy that a core content feed is designed around (just to name a couple examples).
Generative work can be sneakily small scope, but considered large scope
In evaluative work, testing only prototypes limits the sphere of influence that results can have. When generative work is often conflated with strategic work, teams give generative work an undue influence on their decision-making. Generative, small scope work can give the illusion of foundational strategic insights, while being boxed-in, only working towards a local maximum of improvement in a set of features.
Judd Antin categorized UXR work into three levels: macro, middle-ranged, micro. This framework doesn’t map perfectly to my proposed framework, but the concept of “middle-ranged” research highlights a ubiquitous and problematic style of generative interviewing. The middle-ranged research is where we most often see generative tactical work masquerading as strategic work. When researchers aim to answer questions like “do users like this feature?”, “Why don’t users engage with X feature?”, or “Does Y feature meet users’ needs?”, the research appears as though it’s targeting users’ deep underlying needs. In reality, the research scope is small and boxed-in to influence only the existing product offerings.
Middle-ranged research is generative, but not strategic. It will only inform the features at hand (tactical). Strategic generative work uses methods that fully zoom out to the context of users beyond one product manager’s scope. Examples of this are Indi Young’s mental models approach or your favorite flavor of Jobs-to-be-done. These methods are aimed to find truly novel areas of a user’s problems and goals that a product team could work towards enhancing with a new offering or product.
Researchers need to make sure they’re not spending time with constrained generative research in a small scope, expecting it to yield strategically relevant insights. Going back to our original definition of small scope/tactical, when generative research is exploring within an existing product feature set, it can only come up with incremental changes to how a plan to win is implemented.
Moving evaluative research to a strategic scope
UX teams need to make sure their research is highly impactful to bring the most value to their organization. However, the path to this is not reducing evaluative research across the board or simply focusing on generative research. Researchers should do the following to gain more strategic footholds:
- Expand evaluative research to be larger in scope
- Test the full, live app, not just the prototypes
- Use larger N usability testing to get numbers executives listen to and effectively track quality over time
- Ensure that generative research is not sneakily small in scope
- Invest in large scope generative research like mental models or JTBD
Rather than sticking to the conventions of strategic/tactical definitions, let’s consider how the scope of generative and evaluative work influences the eventual impact research will make on an organization’s decisions.
Thanks for Thomas Stokes and Lawton Pybus for their help drafting this post.