tl;dr: When planning a successful survey, ensure the number of invites you need to send is smaller than the number of invites you have available to send by computing the survey viability score yourself or using this calculator.
Early in my career, there were a few questions I didn’t always remember to ask when planning a survey. I sometimes found myself doing underpowered and uninformative work that wasted my time and my stakeholders’ time.
Now, these are the first things I find out when planning a survey – depending on the answer, all subsequent questions about the survey plan are moot.

When planning a survey, you can’t just ask the question “What should our sample size be?”. On its own, this is incomplete information to know if you should run the survey in the first place.
The equally necessary questions are “What is our sampling frame?” and “What is our response rate?”. If you can’t answer these questions, you have no idea if you’ll get the responses you need. And if you don’t get the responses you need, is the survey worth doing in the first place? Starting a survey project without knowing you’ll have the responses you need is like deciding to drive to a distant mountain but not knowing if there are roads or bridges to get there. There are concrete steps you can take to understand if you’ll get the responses you need: compute a survey viability score.
Starting a survey project without knowing you’ll have the responses you need is like deciding to drive to a distant mountain but not knowing if there are roads or bridges to get there.
In this post, I lay out a mathematical way to assess how viable your survey is based on the sample you need vs. the sample you can get. This ratio is quite simple, but there is plenty to consider when getting the values you need to calculate it.
This mainly applies to situations where you control/know your survey pool, and applies less well where you work with vendors to provide the sample from a panel. In that situation, they will provide an incidence rate. In my short time working in the vendor panel space, my only advice is to believe the vendor when they give you the incidence rate.
Key terms

The idea of a sample size is common knowledge on product teams. It refers to the number of data points in a hypothetical sample (subgroup) from a population (entire group). In surveys it often means the number of people that take your survey.1
The next important concept is a response rate. This is the (estimated) number of people that will answer your survey from the number of invites sent. The response rate can vary drastically between groups taking the same survey – highly active or engaged users of a product often are more responsive than inactive or churned users.
A sampling frame is similar to a population but not the same thing. A population is an entire group of people of interest, and the sampling frame is how many can be reasonably reached to take the survey. If you have 10,000 users but only 7,000 users have provided your company with an email, then your sampling frame is 7,000 when your survey tool sends invites via email. In this way, a sampling frame is a tactical consideration based on tooling and resources.
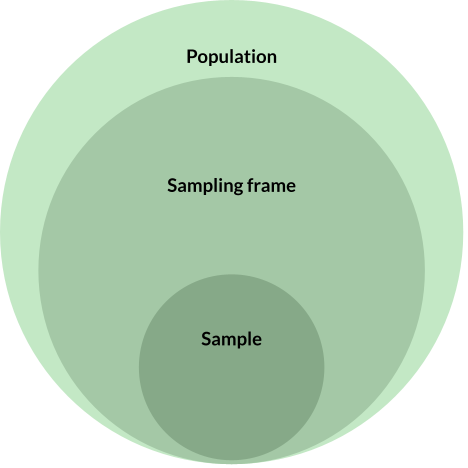
The last important concept is a power analysis. This is a fancy term for how big your sample needs to be for a given analysis. A sample cannot be statistically significant on its own – you need to know how you want to analyze the data to know how big your sample must be. Power is the statistical concept for how well an analysis is set up to detect a particular effect/outcome. You can deep dive here in Quantifying the User Experience (chapters 6, 7, 10) for applied understanding, or take some shortcuts with this blog post.
A simple formula for a Survey Viability (SV) score
Bringing these concepts together, we arrive at a simple calculation (you can do it on your phone calculator) to see how viable your survey is. In plain terms, it will show if the number of users you need to send surveys to is bigger or smaller than the number of users you can send surveys to.
The first part is finding the number of invites you need to send. This first formula alone is quite valuable to know how many survey invites you should be sending: Invites needed = Target Sample Size / Response Rate.
Adding the above into an equation with the sampling frame, we understand the viability of our survey, accounting for how many users we can reach out to. Survey Viability (SV) score:
Invites available / Invites needed
Survey Viability = Sampling Frame / (Target Sample Size / Response Rate)
If your SV is greater than 1, the survey plan will allow for sufficient responses to analyze the data effectively. If your SV is less than 1, you will not have enough power in your study design: this is bad because you can miss real effects or overestimate how important a real effect is.
The SV looks at viability purely from a survey pool resource standpoint. It does not consider whether the question itself is worth answering for your business. And of course, you need to plan and execute the survey launch effectively.
Worked example
The formula itself is quite simple, but many decision points and external factors shape the process of getting the values to input the formula. I’ll illustrate some of these in a worked example.

Let’s imagine our product team of a home fitness app wants to prioritize if the team should focus on adding content for yoga workouts or HIIT workouts to better meet current user needs.
This product question hinges on a multiple choice question in the survey:
Which of the following types of exercises, if any, have you done in the past week?
Running
Cycling
Weight lifting
Yoga
Swimming
HIIT workout
Other
None of the above
To answer the product team’s question, I want to see if more users report doing Yoga or HIIT exercises in the past week. Statistically, I am comparing two proportions (each binary option in a multiple choice question is its own proportion).
Get target sample size
Discussing with the team, we decide we need to see a 10% difference to say that one of these workout types is worth pursuing over the other. (You need to know what particular effect you aim to detect to do a power analysis.) I can then arrive at my target sample size by the analysis I will do.
Simple way
I could just compare the confidence intervals to see if they don’t overlap. We use rough numbers knowing we need a 10% difference that we’d need the margin of error to be at most 5% for each item. Our cheat sheet in the MeasuringU blog tells us we need 381 responses. This approach works in a pinch but unfortunately isn’t as powerful2 as running a simple two-proportion comparison test.
More powerful way
Instead, I’ll do a paired proportion test and run a formal power analysis. There are free calculators online to do the power analysis or you can do it in R. We’ll use the calculator this time for speed and ease.
The tricky thing about power analysis is that you have to do some guesswork no matter what. Most people come to quantitative research for firmness or certainty, but there are lots of human choices in any analysis process.
To do this power analysis, I need to be specific about the expected proportions in the results3. Do we expect users to choose these activities in our question at a rate 50% or 80% or 10%? We may have past internal or external research to estimate, otherwise we’d go with our gut. I will guess that they’re around 25% each, so I put .2 as the expected proportion for Yoga and .3 as the expected proportion for HIIT.

The other pieces we need are the alpha and power. Alpha is typically set at .05 (think p-values) and power is typically set at .8. Alpha is essentially the false alarm rate (chance of finding an effect that isn’t actually real). Power is essentially the miss rate (chance of not detecting a real effect).
Plugging that into the calculator, we get a required sample size of 389 pairs (or survey responses). This is similar to the cheat sheet result, which actually would have made our analysis slightly underpowered, likely because it’s not accounting for what the expected proportions are, in addition to our power. Most of the time, the cheat sheet approach won’t make a huge difference, but it will as your study design gets more complicated with things like multiple analysis groups, covariates, nested data, etc.
Because we did the work, we’re going to go with 389 as our target sample size.
This might seem like a lot, but you get the hang of it quickly. Doing repeated work you build a sense for what meaningful effect could be in your product space and can reuse work from past surveys.
Get sampling frame
In tech products, the surveyable population can be pretty close to the real population. Contacting all current users is easy if you have their emails from signup and a way to send email messages. This is often whittled down by company restrictions like survey cooldown groups or needing users with specific traits. In things like consumer goods, your sampling frame may be a more specialized customer feedback panel. In my past few roles, I typically get the full list of users I could invite by pulling the data from SQL (myself or with a friend in data science).
Regardless of the underlying way you get the data, your sampling frame is the maximum number of people you can send the survey to. For that reason, get the full list even if you don’t plan to send an invite to everyone.
In our case, let’s say we have 300,000 users with accounts in our fitness app. Only 200,000 users have activity in the past month, and we don’t want to target churned/inactive users like those. Of the 200,000 active users, 100,000 are in a survey cooldown and cannot be contacted.
This gives us a sampling frame of 100,000 users.
Get response rate
The best way to see your response rate is to check past surveys you have sent to a similar population. It’s even better if you can look by sub-groups if your survey targets one of them.
A quick google search will say anything from 5% to 50% is a good expected response rate. In my personal experience, rates can even be slightly below 1% depending on your product and user base. While not great to have a response rate below 1%, it’s important to be realistic or you’ll end up wasting time doing a survey that isn’t conclusive (hope is not a strategy).
For our example, we would have done previous survey work and know that monthly active users have a response rate of 1.5%.
Plug it into the formula
When we plug in all of the values to our equation, we get a SV score of 3.85.
Survey Viability = Sampling Frame / (Target Sample Size / Response Rate )
3.85 = 100,000 / (389 / .015 )
The SV score much higher than one, so the survey project is extremely viable based on survey pool resources. In practical terms, I would tell the team let’s plan to run the survey because we’ll be able to answer the question we need to answer (understand if there is a significant 10% difference between users that do Yoga and HIIT workouts).
If you don’t want to use your own calculator, I’ve built one with R Shiny:
Survey viability score calculator
It uses the same exact formula as written above.
When the SV score is less than 1
Our worked example’s sampling frame might be considered luxurious depending on the product space you work in. Many UX researchers work in spaces with only hundreds or thousands of users they can contact. If you only have 10,000 users you can reach out to (which may seem like a lot of people still to certain researchers in B2B spaces or start ups), your SV score is suddenly .38 (much less than 1, not good!).
Or you may have more complex questions than the one above. If you have many users but want to also compare between 3 subscription tiers and one feature being used (yes/no), your target sample size is suddenly 6 times (3 x 2) larger to account for group comparisons. The SV score becomes .64 (also not good!).
These scenarios are common enough, as are many more I haven’t illustrated. So what do you do when the SV score is below 1? That depends on why it’s low and how low it is.
Strategies depending on why your SV score low
All the elements of the SV scores can raise or lower the SV score. If you want to increase your SV score, consider which you have the most control over – focus on impacting that element positively.
- Low response rate
- Write better surveys (shorter, clearer, well-programmed)
- Provide incentivization for the survey
- Use reminders
- Target more effectively
- E.g.: if a survey is related to an event, send it soon after
- Experiment with better invites (A/B test copy and call-to-action)
- High target sample needed
- Include fewer distinct groups by prioritizing project needs
- E.g.: only compare data by user activity level and not geographic location, even if you still include users across countries
- Reduce power analysis requirements
- Reduce your alpha value
- This is not recommended, this should be dictated by criticality to the business and how much risk you want to take.
- Reduce your power
- This is more acceptable, but still not recommended: the risk of missing a real effect should be determined by business requirements.
- Reduce your alpha value
- Include fewer distinct groups by prioritizing project needs
- Small sampling frame
- Consider expanding sampling requirements
- E.g.: allow for users with slightly less activity in a feature
- Unblock new access to users
- E.g.: work with high level stakeholders to get new tools or permissions
- This is unglamorous, slow UX work but can be something most worthwhile for the team if you invest the time.
- E.g.: work with high level stakeholders to get new tools or permissions
- Ignore your survey cooldown pool (in a break-glass insights emergency)
- Consider expanding sampling requirements
How low is too low for an SV score?
It’s clear that an SV score of 1 is good enough for the survey at hand. Considering your organization at large, this may still be too small. An SV score of 1 means that your survey will use all of the available survey invites to meet your target sample size. Keep this in mind during survey planning if you want to send other surveys shortly after without introducing survey fatigue. A simple way to add this into the SV score is to add the number of available invites you want left over after the survey to the sampling frame term.
Your study will be statistically underpowered if the SV score is below 1. If you keep your alpha value (false alarm rate) the same, which you should, then you run the risk of missing a true effect (underpowered). I tend to consider a miss less harmful than a false positive, but both can be detrimental to a company depending on the circumstance.
I could run some simulations (I may still) to see how a lower SV score affects power in survey results. In reality, I typically see a few outcomes from an SV score:
- The score is higher than 1, and I move forward.
- The score is just below 1, we accept slightly less power in the study, and I move forward.
- The score is drastically below 1 and it quickly becomes clear to me as a researcher that a survey is not viable.
I less typically see a situation with a mid-range SV score (like .5-.75) and then work to substantially increase response rates or unlock new access to users. It has happened, but most of the time the survey is able to move ahead or it’s clear a survey will not work at all. Keeping the SV score in your survey kick off task list is a good way to be sure if you have a green light or a red light (or a less likely yellow light).
Discussing low a SV score with stakeholders
It’s helpful to have frank conversations with stakeholders if you can’t reasonably raise your SV score. As a quantitative UX researcher, this is a common reason I suggest against surveys that stakeholders want to do. When I know we’ll likely only get 10-30 responses, I use it as a moment to illustrate how much more value we’d get by running 10 interviews than we would by getting 10 survey responses.
If you think it’s possible to raise your SV score, I wouldn’t necessarily try to explain a survey viability score to stakeholders (unless they want to learn). I would illustrate the effect of power in plain terms. If your SV is low, do a bit of math to find how many responses you’re likely to get (sampling frame * response rate). When you talk to the team, it might sound like, “We’re likely to get 200 responses to our survey when we need about 400 for the analysis. This means we’ll have just a coin flip’s chance4 to find if there is a real 10% difference between these groups. We should think about ways to increase our response rate or expand the pool of users we’ll contact”.
Conclusions
When planning to run a survey from your survey respondent pool, you need to be sure you have the resources you need. It’s as simple as understanding the ratio of survey invites needed to the survey invites available. Because it’s so simple, I often start to use a shorthand to size it up heuristically.
A heuristic approach: you do not need to perform this formal calculation every time you start a project. After being in a team for some time, I do some loose mental math by (1) knowing my users’ normal response rate, (2) assuming a survey will need N=~400 per group (based on 5% confidence intervals) and (3) seeing that a sampling frame is (hopefully) larger than what I’ll need for those typical values.
The Survey Viability score is quite simple, but you’ll need to extend the equation if you have more complicated surveys with subgroups. With 2+ groups that have different sampling frames and response rates, you must compute the SV for each group separately.
As survey practitioners, we’re on the hook for running useful surveys. All other questions of quality and value are moot if we can’t get (near) the survey responses we need. Use the survey viability score to quickly check whether you should start a survey, adjust the inputs to your SV score, or consider another methodology that can provide more value to the team.
Appendix
- An analysis sample size isn’t always the same as the number of users that take a survey. For example, if you show respondents 5 versions of a call-to-action text, your analysis sample size may be your response rate times 5. This is important because you can plan to reach out to fewer users if you gather more data from each user for a certain analysis. ↩︎
- One of my favorite statistical tidbits: if your raw CIs slightly overlap, you may still have statistical significance. This is because in a statistical test you construct a new distribution for the difference in means rather than creating two separate distributions for each mean. Here’s a nice explainer. ↩︎
- We have to be specific about expected proportions because the variance (used to calculate the width of confidence intervals) is tied to the mean in proportional data. This is different from continuous data, where the variance can be the same regardless of how large or small the mean numbers are. In other words, our confidence intervals will be different if the proportion is .5 or .3, even if the sample size is the same. ↩︎
- The same online sample size calculator to find out target sample size can also calculate power with a known sample size. I did this using our main worked example expecting only 200 responses and the power was 51% – this is how I ended up using the coin flip metaphor. ↩︎